I/O流
File类
仅从名字,我们很容易误解File表示一个真实存在的文件,但实际不是这样的
File类表示的含义?
用FilePath来形容它会更加合适,它可以有以下的含义:
- 一个已存在的文件。
- 已存在的目录。
- 尚不存在的文件或目录。
- 这个文件或目录的特性。
- 这个文件或目录的一些操作。
之前在正则表达式中提到正则表达式结合I/O流可以实现对文件的检索。
如何实现文件的检索?
File类中有个public String[] list(FilenameFilter filter)的方法,其中FilenameFilter就是定制过滤规则的接口,这个接口的内如很简单:1
2
3public interface FilenameFilter {
boolean accept(File dir, String name);
}
这是使用了策略模式。
如何向文件中读写数据?
有了文件还无法进行读写的操作,JAVA把能够产生数据输入和输出的数据源称为流,以此来屏蔽I/O设备处理数据的细节。
输入流/输出流
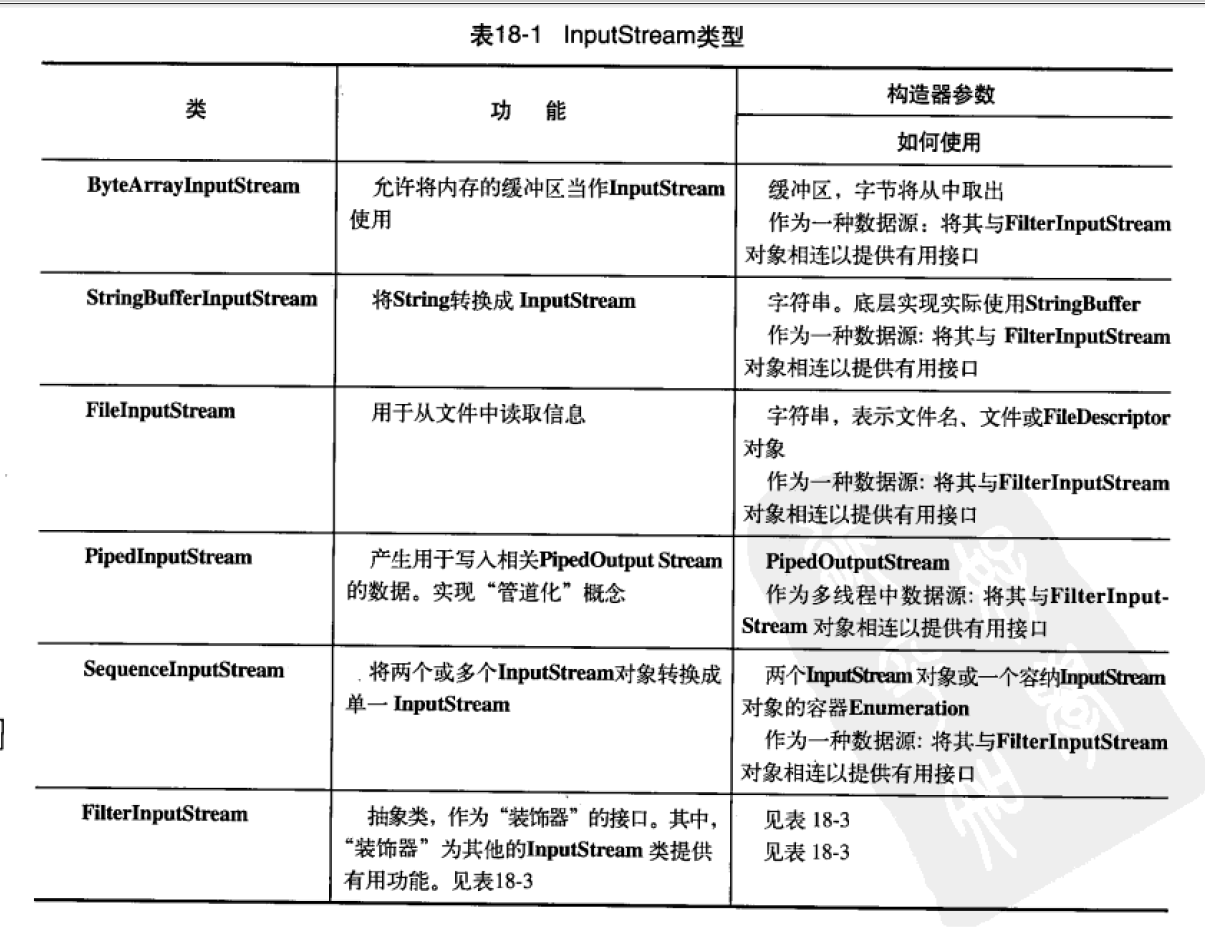
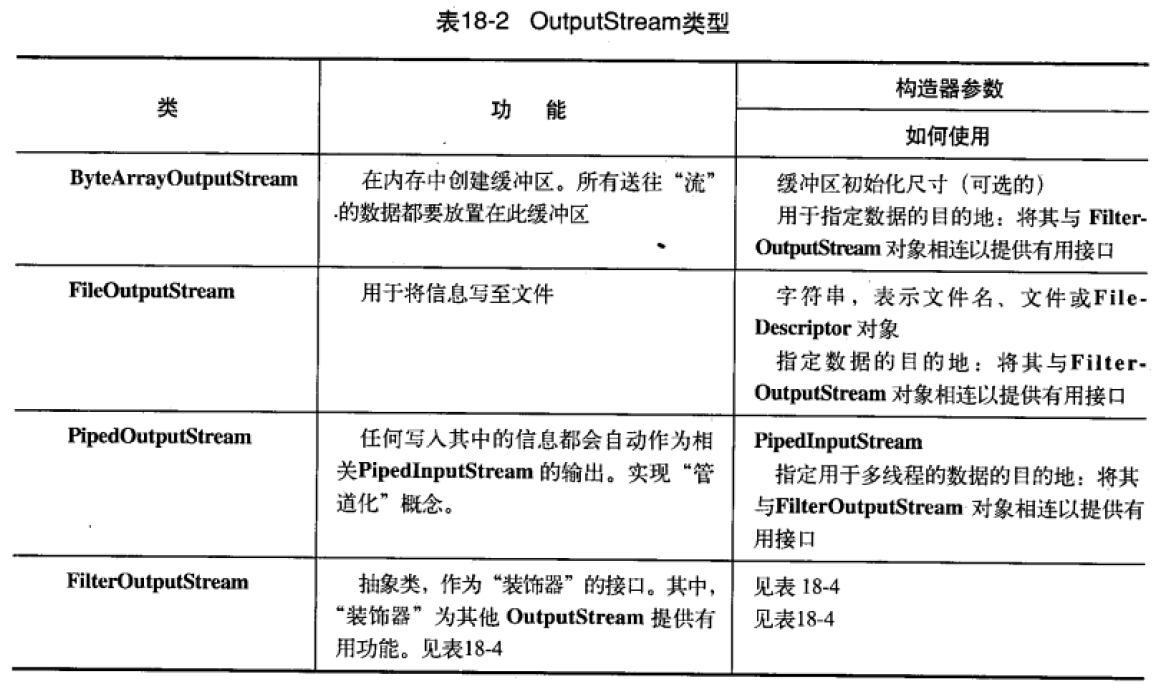
JAVA中用InterStream和Read表示可以产生数据的流,具有read()的方法。
JAVA中用OuterStream和Writer表示可以接口数据的流,具有write()的方法。
比如文件,如果要进行读数据,需要转成文件流(FileInputStream)。
还可以作为数据源的比如:
- 字符串
- 字节数组
- 管道
- 一个由其他种类的流组成的序列
- 其他数据流
读写的方式有很多,因此一半不会直接使用InterStream和Read/OuterStream和Writer里的读写方法,一般都会包装一层,增强读写的功能,这也叫做装饰器模式。
什么是装饰器模式?
先说一个比较通俗的例子,玩游戏的时候,给人物穿戴各种装备,其实就是装饰器模式的一种应用,这个人物还是这个人物(这个接口还是这个接口),只是新的对象具有了更强大的功能。
案例:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52public interface Troll {
void attack();
int getAttackPower();
void fleeBattle();
}
public class SimpleTroll implements Troll {
private static final Logger LOGGER = LoggerFactory.getLogger(SimpleTroll.class);
public void attack() {
LOGGER.info("The troll tries to grab you!");
}
public int getAttackPower() {
return 10;
}
public void fleeBattle() {
LOGGER.info("The troll shrieks in horror and runs away!");
}
}
public class ClubbedTroll implements Troll {
private static final Logger LOGGER = LoggerFactory.getLogger(ClubbedTroll.class);
private Troll decorated;
public ClubbedTroll(Troll decorated) {
this.decorated = decorated;
}
public void attack() {
decorated.attack();
LOGGER.info("The troll swings at you with a club!");
}
public int getAttackPower() {
return decorated.getAttackPower() + 10;
}
public void fleeBattle() {
decorated.fleeBattle();
}
}
上面的ClubbedTroll类就是一个装饰器,把我们的SimpleTroll类给包装了一下,让它更加强大。
说到包装,我们想到我们的适配器。
装饰器和适配器的区别是?
最本质的区别的:
- 适配器会改变被包装的类来适用新的接口。
- 装饰器不会改变接口。
流的装饰器
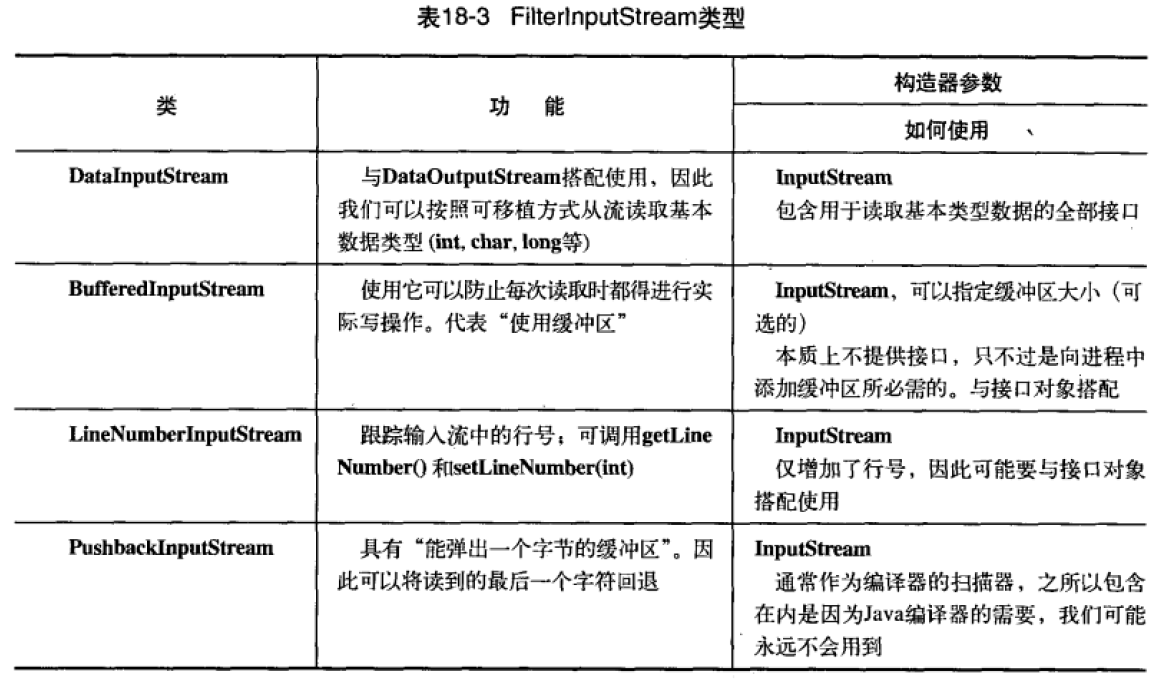
I/O流对象的装饰器都是以FilterInputStream/FilterOuterStream为父类。
装饰什么?
主要分为两类:
- 改变读写方式的装饰器(DataInputStream/DataOuterStream):流读写一般只读写一个字节,为了读写更多的类型,如int,float,boolean,double,char等。
- 在内部提高读写性能的装饰器:如是否缓存,是否保留读写的行,是否把单一的字符推入输入流等等。
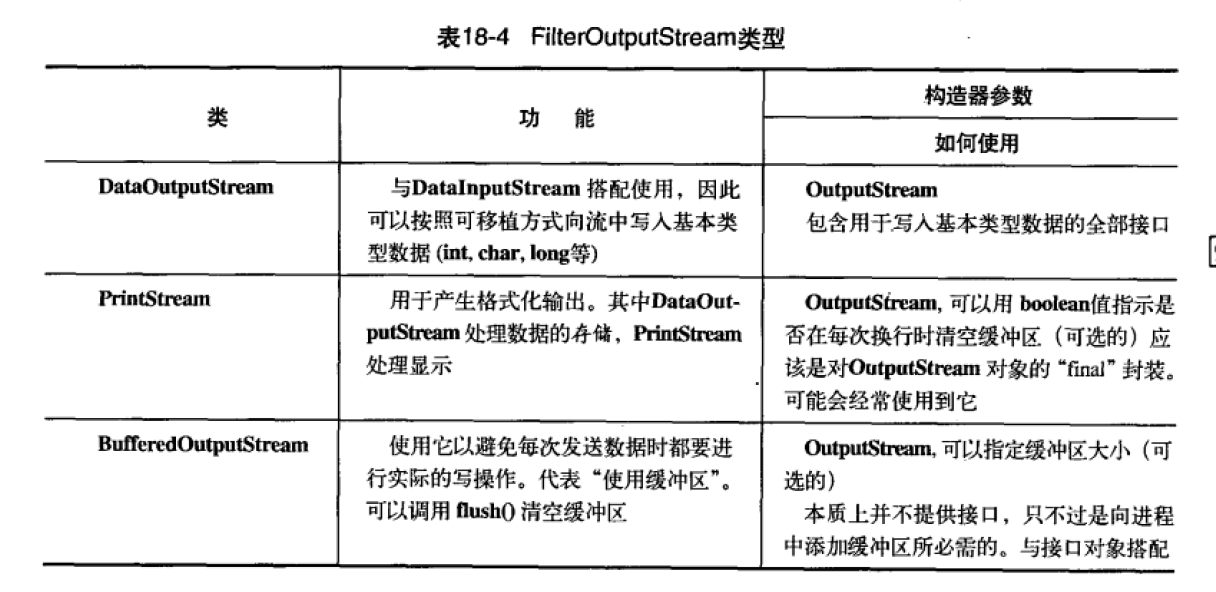
PrintStream和DataOuterStream有什么区别?
PrintStream:格式化的输出基本类型数据
- PrintStream会捕获IO异常,之后使用checkError()来获取输出成功还是失败。
- PrintStream作用是打印基本数据类型的数据,底层使用的是Writer,操作对象是字符(可以选择编码方式),里面使用了Formatter类,因此支持格式化的输出,System.out就是一种PrintStream类。
DataOuterStream:以字节的形式存储基本类型数据
- 将基本类型数据以字节的形式保存在流中,随后搭配的使用DataInputStream来获取这些数据。保持存取的顺序一致,就可以保证获取的数据准确无误。
RandomAccessFile 实现了 DataInput和DataOuter 因此可以看做是DataOuterStream和DataInputStream 的一个综合,除此之外还具有seek()等发方法来定位文件中的某个字节位置。
一个字节一个字节处理的缺陷?
效率低,使用批量读写代替一个字节一个字节处理,增加一个缓冲区来辅助处理——BufferedInputStream/BufferedOutputStream:
如何理解BufferedInputStream的功能?
4个索引:
count:缓冲区有效数据
pos:当前缓冲区内读写的位置
markpos:标记
marklimit:缓冲区大小上限
1个关键函数1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36private void fill() throws IOException {
byte[] buffer = getBufIfOpen();
if (markpos < 0)
pos = 0;
else if (pos >= buffer.length) {
if (markpos > 0) { /* can throw away early part of the buffer */
int sz = pos - markpos;
System.arraycopy(buffer, markpos, buffer, 0, sz);
pos = sz;
markpos = 0;
} else if (buffer.length >= marklimit) {
markpos = -1; /* buffer got too big, invalidate mark */
pos = 0; /* drop buffer contents */
} else { /* grow buffer */
int nsz = pos * 2;
if (nsz > marklimit)
nsz = marklimit;
byte nbuf[] = new byte[nsz];
System.arraycopy(buffer, 0, nbuf, 0, pos);
if (!bufUpdater.compareAndSet(this, buffer, nbuf)) {
// Can't replace buf if there was an async close.
// Note: This would need to be changed if fill()
// is ever made accessible to multiple threads.
// But for now, the only way CAS can fail is via close.
// assert buf == null;
throw new IOException("Stream closed");
}
buffer = nbuf;
}
}
count = pos;
int n = getInIfOpen().read(buffer, pos, buffer.length - pos);
if (n > 0)
count = n + pos;
}
根据if-esle分为以下5中情况:
1.
pos>count:读取完buffer中的数据
且 markpos<0:buffer没有被标记
则 重新覆盖缓冲区数据
1 | private void fill() throws IOException { |
2.
pos>count:读取完buffer中的数据
且 markpos>0:buffer有标记
且 buffer没有多余的空间
则 重新覆盖0到标记处的字节
且 令markpos=0
1 | private void fill() throws IOException { |
3.
pos>count:读取完buffer中的数据
且 markpos=0:表示已没有无效数据可覆盖
且 buffer没有多余的空间
且 buffer.length<marklimit:没有达到扩充上限
则 扩充buffer大小
1 | private void fill() throws IOException { |
4.
pos>count:读取完buffer中的数据
且 markpos=0:表示已没有无效数据可覆盖
且 buffer没有多余的空间
且 buffer.length<marklimit:没有达到扩充上限
则 扩充buffer大小
1 | private void fill() throws IOException { |
5.
pos>count:读取完buffer中的数据
且 buffer有多余的空间
则 写入多余的空间1
2
3
4
5
6
7
8private void fill() throws IOException {
byte[] buffer = getBufIfOpen();
count = pos;
int n = getInIfOpen().read(buffer, pos, buffer.length - pos);
if (n > 0)
count = n + pos;
}
按字节来读写数据的缺陷?
字节流只能很好的处理二进制数据,对于文本数据,使用字节流来处理就会显得格外的麻烦,需要解码才能转成字符串,并且有时候还会因为变长编码出现一些问题,因此采用字符流来读取数据的方式迫在眉睫。由此,JAVA在1.1发布了Reader和Writer。
标准I/O
什么叫做标准?
也就数据源是控制台,从控制台输入输出数据。
System.out 和 System.err都是PrintStream字符流
System.in 是 InputStream 只有读字节的方法read(),因此需要包装一下
NIO
为什么需要NIO?
实际上有两个原因,文件IO和网络IO,文件IO的话好处是提高了读写的速度。网络IO的话是解决了阻塞IO的问题。
书中只谈文件IO的提高,这一节知识点需要补充:socket和selector,以及网络IO方面的知识。
什么是阻塞?
就是进行在进行读写的时候,必须等待,这样效率很低。
如何提高了
- 面向缓冲区:NIO的缓冲区是和操作系统紧密关联的,因此效率更高。
- 面向非阻塞:读写数据的时候不阻塞原应用进程。
- 具有选择器:一个缓冲区可以通过选择器选择不同的通道。
如何使用NIO
这里主要讲解文件IO的使用:
通道和缓冲器一起使用
文件通道:FileChannel
唯一与通道交互的缓冲器:ByteBuffer
旧的I/O库有3个类被重写了,用以产生FileChannel:FileInputStream,FilterOuterStream和RandomAccessFile.- 获取通道getChannel()
- 获取缓冲器ByteBuffer.allocate()或者ByteBuffer.allocateDirect(),后者更接近操作系统,虽然速度会更快,但是分配需额外的开支,需要抉择。
- 从通道读到缓冲器中in.read(buffer),调用filp()来转换缓冲器的状态(实际上是修改了缓冲器的position,limit,capacity),从缓冲器写到通道中out.write(buffer),调用clear再次转换状态(实际上还是修改了缓冲器的position,limit,capacity)。
直接操作缓冲器的方法
put():存
get():取
wrap():包装已经存在的数组
rewind():回到数据的起始点
还是如下图的各种修改缓冲器4个主要索引的方法:
mark()需要配合reset()使用,前一个标记position的位置,后者回到标记点。
clear()和rewind()的区别?
rewind()不会改变position的值。
1 | Buffer clear() |
因为ByteBuffer是处理字节的,那么会有两个问题:
1 如何解决从字节到字符之间乱码问题?
输入到缓冲区前对字节进行编码:”qweqwewq”.getBytes(编码类型)
从缓冲区读取后对字节进行解码:new String(str,编码类型)
使用Charser类做相应的转换:
Charset.forname(编码类型)。
ByteBuffer Charset.encode(CharBuffer)
CharBuffer Charset.decode(ByteBuffer)
2 如何支持更多的基本数据类型
使用视图缓冲器,如下图:
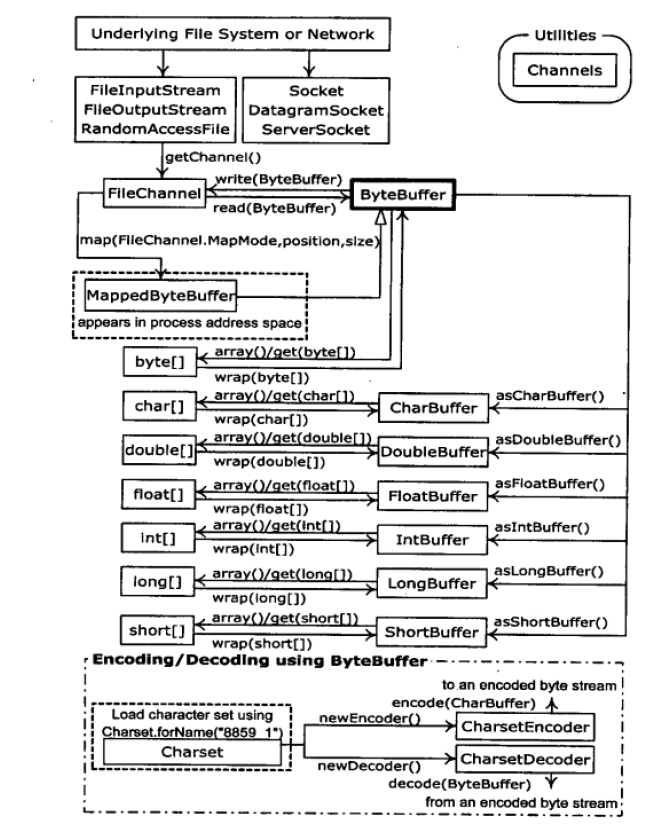
为什么称为视图缓冲器?
从视图缓冲器中读写了基本类型的数据,会使得最基本的ByteBuffer中存放的数据也发生变化。
这样的好处是:方便对基本数据类型的读写,我们可以很方便的把基本数据类型的数据读取到缓冲器中,同时也可以很方便的从缓冲器中将基本数据类型写到通道中。
基本数据类型转成字节后的顺序有何影响?
默认是大端法,可以使用ByteBuffer类里面的 order(ByteOrder.BIG_ENDIAN/ByteOrder.LITTLE_ENDIAN)来修改成小端法。
大端法:高字节在低地址位。
小端法:高梓节在高地址位。
如何操作大文件(2GB)?
一整个大文件可能在内存中放不下,这时候需要使用内存映射文件——RandomAccessFile
使用方法:1
2
3
4
5
6
7
8
9
10public class LargeMappedFiles { static int length = 0x8FFFFFF; // 128 MB
public static void main(String[] args) throws Exception {
MappedByteBuffer out = new RandomAccessFile("test.dat", "rw").getChannel().map(FileChannel.MapMode.READ_WRITE, 0,length);
for(int i = 0; i < length; i++)
out.put((byte)’x’);
print("Finished writing");
for(int i = length/2; i < length/2 + 6; i++)
printnb((char)out.get(i));
}
}
RandomAccessFile会把大文件的小部分一个个放到内存中,隐藏了其它已经交换出去了的部分的细节。
即便传统的IO已经应用NIO优化过了,但是对于大文件的读写,映射内存文件的使用更有优势:1
2
3
4
5
6Stream Write: 0.56
Mapped Write: 0.12
Stream Read: 0.80
Mapped Read: 0.07
Stream Read/Write: 5.32
Mapped Read/Write: 0.02
对数据的读写就涉及到锁的问题,并且系统上的文件竞争的可能是两个完全不同的环境,这时候仅仅使用JVM的加锁可能无法控制,传统的IO没有处理这个问题,NIO如何解决?
NIO的加锁直接映射到本地操作系统的加锁工具
简单的使用案例:1
2
3
4
5
6
7
8
9
10
11
12
13public class FileLocking {
public static void main(String[] args) throws Exception {
FileOutputStream fos= new FileOutputStream("file.txt");
FileLock fl = fos.getChannel().tryLock();
if(fl != null) {
System.out.println("Locked File");
TimeUnit.MILLISECONDS.sleep(100);
fl.release();
System.out.println("Released Lock");
}
fos.close();
}
}
加琐是通道来执行的,还可以使用lock(long position,long size,boolean shared),区别是lock()是阻塞的,tryLock(long position,long size,boolean shared)是非阻塞的。方法中的参数前两个表示加锁的位置,第三个表示是否可共享。
之前说错对资源的异常处理应该使用嵌套try-finally
压缩

使用压缩功能的装饰器
如何使用?
- 单个文件压缩
使用GZIPInputStream或者ZIPInputStream包装一下直接读写即可。
- 多个文件压缩
方式1:
使用ZIPInputStream/ZIPOutputStream,必须结合ZipEntry
ZipEntry:压缩文件中的子文件
ZIPOutputStream.putNextEntry(ZipEntry):指定下一个子文件的名字,注释,等等属性,之后所有的数据都是压缩到这个子文件中。
ZIPInputStream.getNextEntry():指定下一个需要解压的子文件。
如果是解压缩,有更简单的方法,使用ZipFile,提供了enrtyies方法进行遍历每一个ZipEntry。
这是个独立的File,并不是继承File
ZipFile: 压缩文件
确保压缩的文件的正确性?
使用CheckInputStream和CheckOutptuStream计算校验和
jar和zip的区别?(Copy)
JAR 文件格式以流行的 ZIP 文件格式为基础。JAR 格式允许您压缩文件以提高存储效率。与 ZIP 文件不同的是,JAR 文件不仅用于压缩和发布,而且还用于部署和封装库、组件和插件程序,并可被像编译器和 JVM 这样的工具直接使用。在 JAR 中包含特殊的文件,如 manifests 和部署描述符,用来指示工具如何处理特定的 JAR。
序列化
为什么需要序列化?
- 轻量级持久化应用:比如将对象序列化后的序列保存下来,下次程序启动的时候恢复。
- 远程方法调用:在其他计算机上恢复该对象。
如何使用?
- 实现Serializable接口
- 使用ObjectOutputStream/ObjectInputStream读写对象。
对象从序列化恢复的过程需要做哪些工作?
- 寻找Class文件,找不到会抛出异常。
- 反序列化
如何控制需要序列化的字段?
- 使用transiant关键词,取消改字段自动化。
1 | private String username; |
- 实现Externalizable接口,实现readObject()和writeObject()自定义序列化
Externalizable会在一开始调用所有的默认构造器,若无法调用,则无法序列化
1 | public class Blip3 implements Externalizable { |
- 实现Sernalizable接口,也可以做到Externalizable同样的功效,不过要求必须“添加”以下两个方法:
1 | private void writeObject(ObjectOutputStream stream) throws IOException; |
ObjectOutputStream/ObjectInputStream读写时候会使用反射去判断Sernalizable的实现中有没有这两个方法。
在writeObject中调用stream.defaultWriteObject()(必须作为第一个方法),可以使用默认机制写入非transient部分。
序列化后的字节是怎样的?
对象案例:1
2
3
4
5
6
7
8
9
10
11
12
13class parent implements Serializable {
int parentVersion = 10;
}
class contain implements Serializable{
int containVersion = 11;
}
public class SerialTest extends parent implements Serializable {
int version = 66;
contain con = new contain();
public int getVersion() {
return version;
}
}
序列化的结果如下图:


有一个需要注意的点是:上图中开头的4个字节AC ED 00 05是ObjectOutputStream建立的后就会被写入的,即便没有序列化的对象也会有这4个字节,因此如果重复的生成ObjectOutputStream流,会出现AC ED 00 05 AC ED 00 05的情况,这时候后一串AC ED 00 05会被当做对象字节处理,这时候会抛出StreamCorruptedException异常,如何解决?
AC ED 00 05的信息是由 ObjectOutputStream.writeSystemHeader()写进入的,因此对于之后重复创建的ObjectOutputStream流,必须重写这个方法,使其不写入这些头信息。
反序列化后的对象(包括对象里的对象)是否一样?
说到一样,就涉及到内容一样(地址不一样,深复制)和地址一样(浅复制)。
关于这一部分内容下面的链接可供学习:
[深复制和浅复制]https://www.cnblogs.com/yxnchinahlj/archive/2010/09/20/1831615.html
使用序列化是深复制。
但是需要注意的是,在单一流里,相同的对象序列最后反序列化对来的对象地址是一样的。
static会被序列化么?
序列化的是对象的状态,static的信息是类的状态,放在静态区中,因此不会被序列化。如果希望传递static字段的值,需要把这个值给序列化,之后反序列后重新赋值。
XML
Serializable的序列化字节只有JAVA才能反序列化,XML是国际上约定的一种序列化文本,可供JAVA和其它各种语言来进行序列化和反序列化。意味着一个XML文件,往往对应着JAVA中的一个或者多个对象。
java语言有XOM类库支持转换XML的简单使用。
Preferences
一种更小更简单的序列化方式,同时也比较有限。JAVA中preferences类提供支持。

